メンバー
| 氏名 | 所属 | 役割 |
|---|---|---|
| 渋谷 哲朗 | 東京大学 医科学研究所 | グループ代表 |
| 小野寺拓 | 東京大学 医科学研究所 | 研究メンバー |
| 李 東揆 | 東京大学 医科学研究所 | 研究メンバー |
| 李 楊 | 東京大学 医科学研究所 | リサーチアシスタント |
| 定兼 邦彦 | 東京大学 大学院情報理工学系研究科 | 研究メンバー |
| 伝住 周平 | 東京大学 大学院情報理工学系研究科 | 研究メンバー |
| 李 太斗 | 東京大学 大学院情報理工学系研究科 | リサーチアシスタント |
| 竹田 正幸 | 九州大学 大学院システム情報科学研究院 | 研究メンバー |
| 坂本 比呂志 | 九州工業大学 大学院情報工学研究院 | 研究メンバー |
| 高畠 嘉将 | 九州工業大学 大学院情報工学研究院 | リサーチアシスタント |
| 坂本 時緒 | 九州工業大学 大学院情報工学研究院 | リサーチアシスタント |
| 谷川 眞一 | 京都大学 数理解析研究所 | 研究メンバー |
| 中野 眞一 | 群馬大学 大学院理工学府 | 研究メンバー |
| 矢田 勝俊 | 関西大学 商学部 | 研究メンバー |
| 喜田 拓也 | 北海道大学 大学院情報科学研究科 | 研究メンバー |
| 正木 拓也 | 北海道大学 大学院情報科学研究科 | リサーチアシスタント |
研究項目:ビッグデータを対象とする劣線形データ構造の基盤創出
 近年の多くのビッグデータにおいて,ムーアの法則をはるかに凌駕する勢いでデータ量が増加しているが,このようなデータに対して解析等を行うことが今現在できていたとしても,それが線形時間アルゴリズムであったり,線形サイズのデータ構造を必要とするものであったりすると,早晩その解析が破綻することは明らかである.これに対し,劣線形時間あるいは劣線形スペースでデータを処理することが可能なデータ構造,すなわち劣線形データ構造の開発やそのためのパラダイムを構築することができれば,そのような破綻を回避できる可能性がある.そこで,本グループは,ビッグデータの検索や解析の効率化・高精度化のための新しい劣線形データ構造の開発を行う.
近年の多くのビッグデータにおいて,ムーアの法則をはるかに凌駕する勢いでデータ量が増加しているが,このようなデータに対して解析等を行うことが今現在できていたとしても,それが線形時間アルゴリズムであったり,線形サイズのデータ構造を必要とするものであったりすると,早晩その解析が破綻することは明らかである.これに対し,劣線形時間あるいは劣線形スペースでデータを処理することが可能なデータ構造,すなわち劣線形データ構造の開発やそのためのパラダイムを構築することができれば,そのような破綻を回避できる可能性がある.そこで,本グループは,ビッグデータの検索や解析の効率化・高精度化のための新しい劣線形データ構造の開発を行う.ビッグデータは,単純なランダムなデータの集積ではなく,通常は何らかの目的をもって集められたデータである.このことは,ビッグデータの情報量が実は見かけほど大きくはない可能性があることを意味する.そのような「実は」情報量の少ない「ビッグデータ」は,うまく効率的に処理できる劣線形データ構造を持つ可能性は高いと思われる.そこで本グループでは,以下にあげる3つの異なるアプローチを用いて劣線形データ構造研究を行い,現実のビッグデータ解析・検索へつなげていくことをめざす.
- 情報論的アプローチによる劣線形データ構造の開発 1つ目のアプローチでは,ビッグデータの実際の情報科学的な情報量に着目し,データをもとのサイズよりも小さく,できれば劣線形サイズで保持しながら解析,検索を行う技術を開発する.ビッグデータが圧縮できている場合に,その情報を圧縮して保持したまま解析することができれば,データ量Nに関する時間ではなく,その圧縮したデータ量すなわち情報量Hに関する計算時間で計算できる可能性がある.また,データの格納領域が小さいまま計算できれば,I/O計算量や並列化時の通信計算量,あるいはメモリの小さいGPGPUにおける実計算量なども減らすことができる可能性がある.さらに,一般的には情報量に対して劣線形サイズの厳密索引は情報論的に不可能であるが,現実のビッグデータにおいては,情報量の定義を巨大データに対して正確に定義することが難しく,現実のデータと情報量の定義に乖離があるような場合が考えられる.また,必ずしも厳密な索引を要しない場合も考えられる.そういった場合には,この情報論的不可能性は打破できる可能性がある.このアプローチでは,文字列等の基礎的データ構造に対し,圧縮したままのデータ検索・解析を行う新しい情報科学パラダイムの創出をめざす.
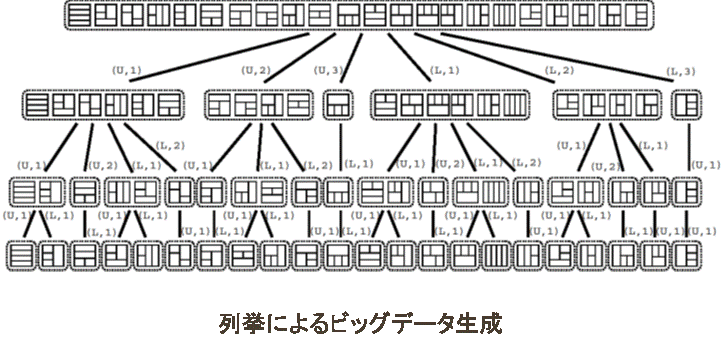
- 列挙論的アプローチによる劣線形データ構造の開発 2つ目のアプローチでは,列挙アルゴリズムがきわめて少ない情報量からビッグデータに匹敵する巨大データを生成することができることに注目し,そのような巨大データに対する劣線形データ構造の研究を行う.このように生成された巨大データに対して解析を行う場合,解1つあたり定数時間で計算できるようなアルゴリズム,すなわち列挙データ数に関して線形時間のアルゴリズムは効率的であるとはいえない.列挙データにおいては,そのデータの生成規則はわかっているため,それを活用した効率的アルゴリズムを考えることが,これまでも行われてきている.しかし,そのようなきれいなモデルに基づいて生成された「均一な」データでは効率的なアルゴリズムが存在しても,その均一性が破れると効率的ではなくなってしまうことが多い.このように現実のビッグデータがきれいなモデルからの生成データであるということはほとんどないため,均一性が多少破れているデータに対しても効率的な解析が行えるような柔軟なデータ構造が要求される. このアプローチでは,このような列挙アルゴリズムの観点から,不均一列挙データに対する検索や索引のための劣線形アルゴリズムを列挙理論の観点からパラダイム創出をめざす.
- 実応用アプローチによる劣線形データ構造の開発 3つ目のアプローチでは,情報科学的な一般的な枠組みだけでなく,実際の現実のデータが持つ様々な実際の性質も活用したより具体的な劣線形データ構造の開発を行い,それによって,実際の解析や検索を効率よく行うことをめざす.さらに,そのような具体的応用研究を通じて,これまでの情報科学理論で捉えられなかった新しいデータ構造研究のパラダイムを構築することもめざす.現実のデータとしては,タンパク質立体構造データ,次世代シークエンサーデータ,店舗のPOS・センサーデータなどの経営データ等を対象とする.このアプローチでは,これらの多岐にわたる具体的研究を通じてそれらに共通するデータ構造パラダイムの創出も狙っていく.