Abstract
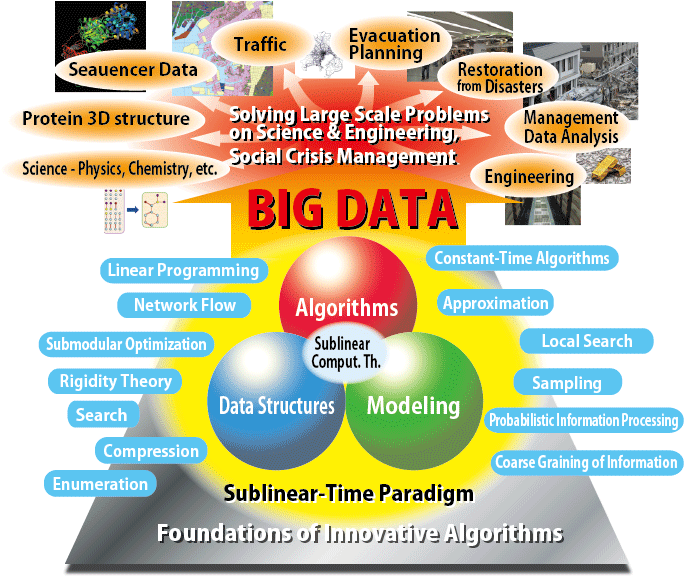
We are demanding innovative changes to algorithm theory for big data
which is attracting attention this century, because of the huge size of the data.
For example, we have considered that polynomial time algorithms has been "fast" in the past,
but if we applied an O(
n2) time algorithm for the big data which has peta byte scale or more,
we would encounter problems on the computational resource or the running time.
Therefore, we require linear, sublinear, or constant time algorithms for the problems.
In this project, we suggest a new paradigm
Sublinear-time Paradigm for supporting the innovation,
and we construct a foundation of innovative algorithms
by developing algorithms, data structures, and modeling techniques for the big data.
What's New!